# 크롤링을 막아놓은 사이트에 대한 대처
selenium모듈을 설치해준다.
Terminal 에 pip install selenium
크롬드라이버 설치
버전확인 : 크롬 우측상단 크롬 맞춤설정 및 제어 - 도움말 - 크롬정보
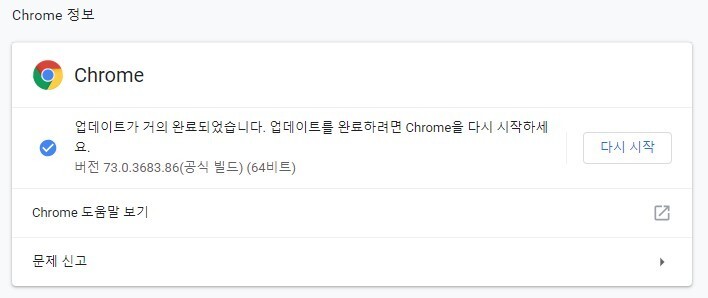
본인 크롬버전 확인 : 73버전

버전에 맞게 설치

윈도우 환경이므로 win32 다운로드, 압축푼뒤

파이썬 폴더에 드래그 앤 드롭 하면 exe파일이 들어가진다.
<pre style="font-family: 굴림체; font-size: 9pt;">from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get('https://nid.naver.com/nidlogin.login') # 로그인페이지 불러오기
# 아이디/비밀번호를 입력해준다.
driver.find_element_by_name('id').send_keys('my_id')
driver.find_element_by_name('pw').send_keys('my_pw')
driver.find_element_by_xpath('//*[@id="frmNIDLogin"]/fieldset/input').click() # 로그인버튼을 클릭</pre>실행시 결과

네이버의 경우 아이디, 비밀번호에 무작위 대입공격에 대비해
'아래 이미지를 보이는대로 입력해주세요'
captcha라고 하는 보안시스템이 뜨게된다.
구글에서 만든시스템으로 글자,숫자를 입력하거나,
다음 사진중 신호등을 선택하시오, 간판을 선택하시오 등이 이에 해당한다.
# 한곳의 사이트를 정해서 캐오고싶은 정보를 캐와보자
네이버 뉴스에서 가장 많이본 뉴스를 분야별로(정치, 경제, 사회 등) 순위를 캐오고싶다.

이부분으로 먼저 개발자도구에서 소스확인

"category"에는 정치 경체 사회 생활/문화 세계 IT/과학 에 대한 내용이
"right.ranking_contents"에는 1~10번까지의 기사내용에 해당하며,
한번 불러온뒤 두개를 나눠서 불러오기위해 우선 상위"section section_wide"를 요청한다.
import requests
from bs4 import BeautifulSoup
URL = 'https://news.naver.com/main/ranking/popularDay.nhn' # 변수저장
res = requests.get(URL) # res에 해당 링크의 소스를 get방식으로 저장
bsObject = BeautifulSoup(res.text, "html.parser")
news = bsObject.find("div", class_="section section_wide") # div 태그에 클래스이름에 해당하는것을 찾아서 저장
print(news)news가 제대로 출력됨을 확인후
cate_head = news.find("span", class_='category_ranking') # cate_head에 태그명 span중에 클래스명을 찾아서 저장해라
news_category = []
for atag in cate_head.find_all('a'): # atag에 cate_head에서 a태그를 모드 찾아서
news_category.append(atag.string) # 문자형으로 리스트에 추가해라
print(news_category)출력
['정치', '경제', '사회', '생활/문화', '세계', 'IT/과학']제목을 뽑아오는데 성공했다.
이제 1~10순위의 기사를 가져와야한다
news_ranking = []
for rank in bsObject.find_all("ul", class_ = 'section_list_ranking'): # bsObject에서 ul태그, ''클래스명을 찾아서
news_ranking.append(rank.text) # 텍스트로 리스트에 추가해라
print(news_ranking)
출력
['\n1 산불 현장 찾은 문 대통령 "무사하게 피신해주셔 고맙습니다" \n2 이언주 "찌질한 징계, 바보들 마음대로........기사순위를 가져오는데 성공했다.
최종
import requests
from bs4 import BeautifulSoup
URL = 'https://news.naver.com/main/ranking/popularDay.nhn' # 변수저장
res = requests.get(URL) # res에 해당 링크의 소스를 get방식으로 저장
bsObject = BeautifulSoup(res.text, "html.parser")
news = bsObject.find("div", class_="section section_wide") # div 태그에 클래스이름에 해당하는것을 찾아서 저장
cate_head = news.find("span", class_='category_ranking') # cate_head에 태그명 span중에 클래스명을 찾아서 저장해라
news_category = []
for atag in cate_head.find_all('a'): # atag에 cate_head에서 a태그를 모드 찾아서
news_category.append(atag.string) # 문자형으로 리스트에 추가해라
print(news_category[5])
news_ranking = []
for rank in bsObject.find_all("ul", class_ = 'section_list_ranking'): # bsObject에서 ul태그, ''클래스명을 찾아서
news_ranking.append(rank.text) # 텍스트로 리스트에 추가해라
print(news_ranking[5])
출력
IT/과학
1 '갤럭시S10 5G' 인기…LGU+ "초기 물량 완판"(종합)
2 4년 전으로 되돌아간 삼성전자 살아날까
3 토스, ‘토스카드’ 출시..."토스머니로 온·오프라인 결제"
4 5G폰 일반 개통 첫날…이통사 '과열경쟁' 조짐
5 [5G 일반 개통 첫날] 5G 열기에···이통사 '공시지원금 투하' 경쟁
6 [촌철살IT] 구미 간 삼성맨은 퇴사, 포항공대 졸업생은 강남·판교 와 창업
7 고성·속초 산불, 통신복구 500여명 '총력전'(종합)
8 화웨이 논란에도… LG유플러스 5G 개통 첫날 ‘활짝’
9 단통법 위반도 불사…'갤S10 5G' 지원금 경쟁 치열
10 LG전자 1분기 이익 전망치 웃돌아…생활가전이 '체면치레'
원하는대로 결과가 제대로 출력이 된다.
#회고
코드 진행은 굉장히 초보적인수준으로 쭉 나열해놓아서 조금더 줄이고 간단하게 만들 수 있을수도 있을것 같다.
다음 크롤링때 빼온 내용으로 DB에 업로드하고, php에서 불러와 뿌려주는것 까지 하려면 현 상태까지만 해야겠다.
어쨋든 거의 일주일동안 붙잡고있던게 해결이 되었으니, 이제 다른 아이디어로 여러사이트들을 크롤링 해볼까한다
'python' 카테고리의 다른 글
| [단순반복작업은 파이썬으로!] 엑셀 빅(?)데이터 간단 작업 (0) | 2021.11.22 |
|---|---|
| 크롤링 완성(?) (0) | 2021.11.22 |
| 웹 스크랩핑(크롤링) (0) | 2021.11.18 |
| Python - 기초개념2 (0) | 2021.11.18 |
| Python - 기초개념 (0) | 2021.07.09 |